Appearance
Top-Down Parsing
The section begins with a general form of top-down parsing, called recursive-descent parsing, which may require backtracking to find the correct
Recursive-Descent Parsing
Consider the grammar
To construct a parse tree top-down for the input string
- Since
has only one production, we use it to expand and obtain the tree of the lhs of the figure below. - The leftmost leaf, labeled
, matches the first symbol of input , so we advance the input pointer to . Now, use the first alternative to obtain the tree of the middle of the figure below. - Since
does not match , we report failure and go back to and retract the input pointer to seek for another alternative producing a match. The second alternative produces the tree of rhs of the figure below. The leaf and match to the second and the third symbols of respectively, we halt and annouce successful completion of parsing.

Noted that a left-recursive grammar can cause a recursive-descent parser, even one with backtracking, to go into an infinite loop. That's why we've talked about the elimination of left recursion. Also, the backtracking is not an efficient way to construct a parse tree, thus we shall see how to predict the right alternative below.
FIRST Set
Why FIRST
Consider the production rule
Assume the input string is
In this case,

Rules for FIRST set
To compute
- If
is a terminal, then . - If
is a nonterminal and is a production for some - Place
in if for some , is in , and is in all of , i.e., . - Add
to if is in for all .
- Place
- If
is a production, then add to .
Elaboration on the Rules
- For example, suppose
, then , where and are terminals - For example, everything in
is surely in . If does not derive , then we add nothing more to , but if , then we add , and so on. - The rule should be self-explanatory.
A simple example
Consider the production rules below
Find the FIRST sets for the nonterminals
Solution
FIRST(F) = {(}
FIRST(F) = {(, id}
FIRST(E') = {+}
FIRST(E') = {+, ε}
FIRST(T') = {*}
FIRST(T') = {*, ε}
FIRST(T) = FIRST(F) = {(, id}
FIRST(E) = FIRST(T) = {(, id}
| Nonterminal | FIRST Set |
|---|---|
FOLLOW Set
Why FOLLOW
Consider the production rule
Suppose the string to parse is
In this case,

Rules for FOLLOW set
To compute
- Place
in , where is the start symbol and is the input right endmarker. - If there is a production
, then everything in except is in . - If there is a production
, or a production , where contains , then everything in is in .
A simple example
Continue the example above
| Nonterminal | FIRST Set |
|---|---|
Find the FOLLOW sets for the nonterminals
Solution
FOLLOW(E) = {$}
FOLLOW(E) = {$, )}
FOLLOW(E') = FOLLOW(E) = {$, )}
FOLLOW(T) = FIRST(E') - {ε} = {+}
FOLLOW(T) = {+} ∪ FOLLOW(E) = {+, $, )}
FOLLOW(T') = FOLLOW(T) = {+, $, )}
FOLLOW(F) = FIRST(T') - {ε} = {*}
FOLLOW(F) = {*} ∪ FOLLOW(T) = {*, +, $, )}
| Nonterminal | FOLLOW Set |
|---|---|
LL(1) Grammars
Predictive parsers, that is, recursive-descent parsers needing no backtracking, can be constructed for a class of grammars called LL(1).
- The first "L" in LL(1) stands for scanning the input from left to right,
- The second "L" for producing a leftmost derivation
- The "1" for using one input symbol of lookahead at each step to make parsing action decisions.
Definition of LL(1) grammars
A grammar
- No left-recursion or ambiguity
- For no terminal
do both and derive strings beginning with . - Equivalent to that
and are disjoint sets.
- Equivalent to that
- At most one of
and can derive the empty string. - If
, then does not derive any string beginning with a terminal in , and vice versa. - Equivalent to that if
is in , then and are disjoint sets, and vice versa.
- Equivalent to that if
Nonrecursive Predictive Parsing
Construction of a predictive parsing table
For each production
- For each terminal
in , add to - If
is in , then for each terminal in , add to . If is in and is in , add to as well.
Finally, set
Use the same grammar above for example, but we'll use the standard BNF for a clearer view
| Nonterminal | FIRST Set | FOLLOW Set |
|---|---|---|
For E -> TE'
1. M[E, (] = E -> TE'
M[E, id] = E -> TE'
For E' -> +TE'
1. M[E', +] = E' -> +TE'
For E' -> ε
2. M[E', )] = E' -> ε
M[E', $] = E' -> ε
For T -> FT'
1. M[T, (] = T -> FT'
M[T, id] = T -> FT'
For T' -> *FT'
1. M[T', *] = T' -> *FT'
For T' -> ε
2. M[T', +] = T' -> ε
M[T', )] = T' -> ε
M[T', $] = T' -> ε
For F -> (E)
1. M[F, (] = F -> (E)
For F -> id
1. M[F, id] = F -> id
PREDICT sets and LL(1) verification
In some literature, the predictive parsing table can be viewed as PREDICT sets. For each production
| Production | PREDICT Set |
|---|---|
We can further combine the 2nd and 4th conditions in the definition of LL(1) grammars into the examination of PREDICT sets. LL(1) contains exactly those grammars that have disjoint PREDICT sets for productions that share a common left-hand side. That is, at most one production can be added into each entry in the predictive parsing table
Example
| Production | PREDICT Set |
|---|---|
LL(1)!
| Production | PREDICT Set |
|---|---|
LL(1)!
| Production | PREDICT Set |
|---|---|
LL(1)!
Table-driven predictive parsing
Model of a table-driven predictive parser
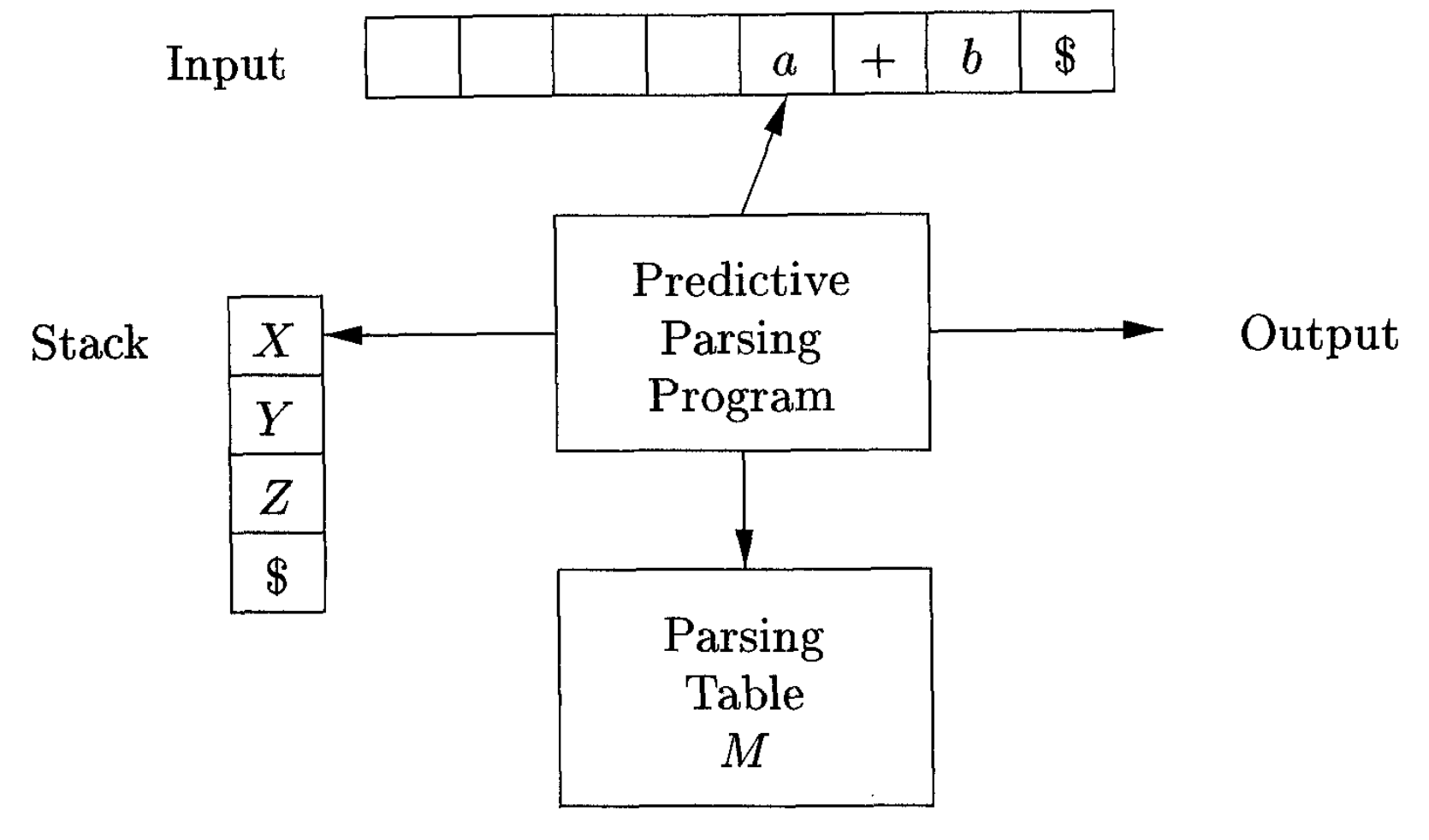
Image credit to Compilers: Principles, Techniques, and Tools 2nd Edition
- Input: A string
and a parsing table for grammar . - Output: A leftmost derivation of
or an error indication.
Initially, the parser is in a configuration with
- Set the input pointer
to point to the first symbol of - Set
to the top stack symbol and while do the following
- If
is , pop the stack and advance . - Else if
is a terminal or is an error entry ,error out. - Else if
- Output the production
- Pop the stack
- Push
onto the stack, with on top
- Output the production
- Else if
- Set
to the top stack symbol.
Example
Continue from above
Moves made by a predictive parser on input
| Matched | Input | Action | Stack |
|---|---|---|---|
| output | |||
| output | |||
| output | |||
| match | |||
| output | |||
| output | |||
| match | |||
| output | |||
| output | |||
| match | |||
| output | |||
| match | |||
| output | |||
| match | |||
| output | |||
| output |
